
Spam or Ham - NLP & Classification


Project Objective
Build a model to classify SMSes into spam or ham (non-spam).
Methodology
In this project, Natural Language Toolkit (nltk) is used to perform text processing and vectorization. Vectorized corpus were then fed to 3 machine learning models (Naive Bayes, SVC and Random Forest) for classification.
Dataset Used
Dataset gotten from UCI Machine Learning Repository
Basic EDA
import nltk
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
messages = pd.read_csv('smsspamcollection/SMSSpamCollection', sep='\t', names=["label", "message"])
messages.head(10)

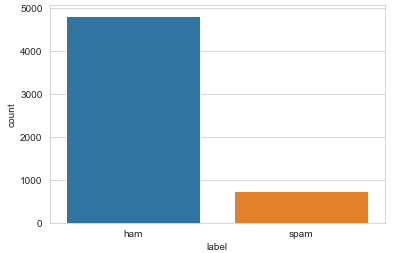
sns.countplot(data=messages,x='label')
plt.show()
# explore the length of messages
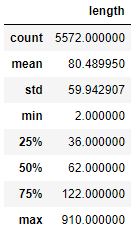
messages['length'] = messages['message'].apply(len)
messages.describe()
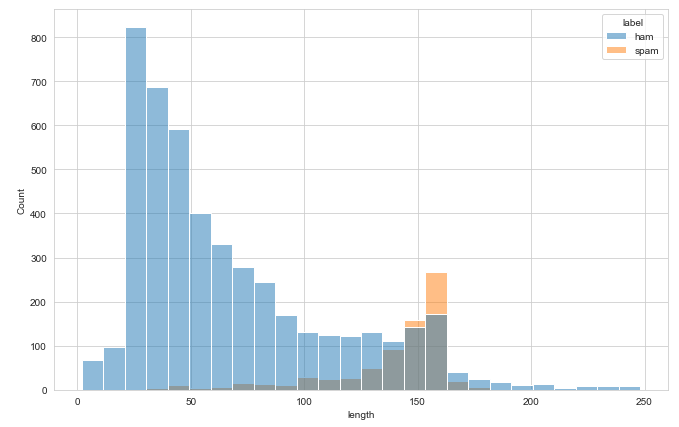
plot = messages[messages['length'] < 250]
plt.figure(figsize=(11,7))
sns.histplot(data=plot,x='length',hue='label')
Text Processing & Model Building
# define a function to remove non-words & stopwords
from nltk.corpus import stopwords
def clean_tokenize(string):
word = [s.lower() for s in string.split() if s.lower() not in stopwords.words('english')
and s.isalpha()==True]
return word
Next, we perform train test split and create a pipeline to carry out the workflow of vectorization, TF-IDF transformation, model fitting and prediction.
# train test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(messages['message'], messages['label'], test_size=0.3)
# set up a pipeline
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
model = [MultinomialNB(), RandomForestClassifier(), SVC()]
result = {}
for m in model:
pipeline = Pipeline([
('bow', CountVectorizer(analyzer=clean_tokenize)),
('tfidf', TfidfTransformer()),
('classifier', m)])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
result[m] = classification_report(y_test,y_pred)
for k, v in result.items():
print(k,'\n',v)
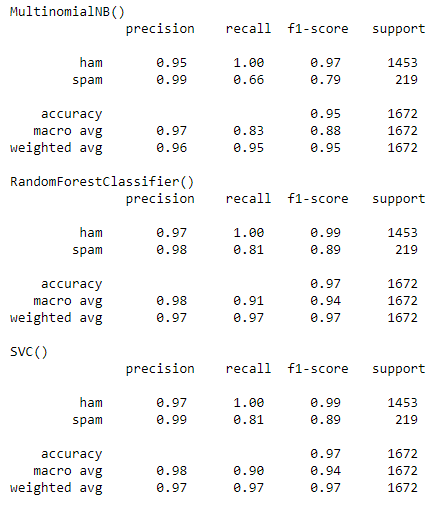
Random Forest seems to produce the best result based on accuracy, recall and f1 score.
Future Improvement
- The messages in this dataset consists of many ‘Singlish’ words (Singaporean-English - localized English in Singapore), short-form and mis-spelled words. Other open source tools from nltk or textblob etc can be explored to help fix this issue.
- More fine-tuning can be done on the models
Written on May 3, 2022